EdTech batch integration architecture



Progression logic that works in staging breaks in production when sync boundaries are not defined as an architectural constraint. Most edtech integration failures do not come from complex bugs — they come from a gap between when an event happens in an LMS or SIS and when the downstream system learns about it. In a batch-based environment, that gap is structural. Treating it as an edge case is what creates inconsistency.
This article is for integration architects, district IT teams, and edtech vendors who design or operate learning platforms that rely on scheduled data exports rather than real-time APIs. Next — a framework for building EdTech batch integration architecture that handles ingestion, validation, reconciliation, and audit traceability in a deterministic way, so progression logic stays consistent across sync cycles. For teams building or scaling edtech platform engineering products, this is the design layer that most often determines whether institutional clients trust the system.
EdTech batch integration architecture is a structured approach to ingesting, validating, and processing scheduled data exports — typically CSV or fixed-format files from SIS and assessment platforms — so that learning progression logic produces consistent, auditable results across every sync cycle. It defines ingestion schedules, schema validation rules, idempotent processing mechanisms, reconciliation checkpoints, and visibility boundaries. Without this structure, progression behavior becomes sensitive to timing, export format changes, and the order in which files arrive.
Why education platforms still run on batch exports
The assumption that modern education platforms should have real-time APIs misses how most district infrastructure actually works. Student Information Systems export enrollment data on a nightly schedule. Assessment tools generate CSV reports at defined intervals. Learning platforms provide read-only dashboard access without API endpoints. Data corrections happen asynchronously, sometimes days after the original event. These are not temporary limitations waiting to be resolved — they reflect deliberate procurement choices, vendor lock-in, and regulatory data residency constraints that shape how institutions buy and configure software.
The U.S. Department of Education data standards resources document batch-based data exchange as the common integration model across K-12 and higher education institutions — including institutions with modern infrastructure. For districts running legacy SIS platforms, structured exports remain the only integration method available. This is the environment a well-designed edtech integration architecture must account for.
The four constraints that make real-time unavailable
- Vendor export model: SIS and assessment platforms often offer scheduled exports as their primary external data interface, with no REST or event-based API.
- Data residency policy: Institutional contracts may restrict where student data can be transmitted and when, making continuous streaming incompatible with compliance requirements.
- Legacy infrastructure: Many districts operate on-premises SIS systems where API access would require significant vendor engagement and additional licensing.
- Procurement cycles: District technology decisions move slowly. Integration methods that were selected during procurement remain in place through the full contract term, typically three to five years.
Designing around these constraints rather than assuming they will change is what separates a functional integration architecture from one that requires constant workarounds.
Why Batch Does Not Equal Real-Time
A nightly CSV export can look like it is almost real-time — data arrives regularly, systems seem synchronized, and nothing appears obviously broken. The gap between appearance and behavior is where integration failures accumulate. A scheduled export captures system state at one specific moment. It does not record when events actually occurred, it does not reflect changes that happened after the export window closed, and it does not guarantee that downstream systems are evaluating current data when a decision is made.
Three misassumptions show up consistently in teams that are new to batch-based integration design: that enrollment updates reflect immediately in progression rules, that assessment completions become available as soon as a student submits, and that override changes propagate across systems without delay. All three are real-time assumptions applied to a batch environment. The result is progression logic that produces correct behavior under test conditions — where data is pre-loaded — and incorrect behavior under production conditions, where data arrives at defined intervals.
The timing gap that causes progression errors
The mechanics of the gap are specific enough to be worth describing concretely. A student completes an assessment module at 10:00 AM. The SIS export runs at midnight. The LMS ingestion job runs at 1:00 AM. Progression evaluation runs at 2:00 AM. At 2:00 AM, the system is evaluating data that was already fourteen hours old when it was exported. If the student's completion is not in the midnight export — because the SIS recorded it at 11:59 PM — it will not appear until the following night's cycle.
This is not an unusual edge case. It is the default behavior of any batch system where event time and export time are decoupled. Progression logic that does not explicitly account for sync boundaries will evaluate incomplete data without any visible error, producing incorrect mastery states or blocked learning paths. Fixing these failures after the fact is operationally expensive. Designing the sync boundary into the progression rules from the start is the correct approach.
How to design deterministic ingestion for batch-based learning systems
Deterministic ingestion means the same input always produces the same output, regardless of when the job runs or how many times it is retried. This is not the default behavior of a batch pipeline — it requires explicit design choices at each step of the ingestion process. Teams that skip this design step end up with pipelines that process some records twice, silently skip malformed rows, and produce different progression states depending on the order of execution.
For Boomi integration for education platforms, deterministic ingestion design typically involves four specific controls:
Schema validation, idempotency, and error isolation
- Schema validation before processing. Every CSV export must be validated against an expected structure before any transformation logic runs. Field order, data types, required columns, and encoding must be enforced. A file that passes validation has a known structure. A file that fails validation should be rejected entirely and logged — not partially processed.
- Version control of data formats. When SIS vendors modify export layouts — renaming columns, reordering fields, changing date formats — ingestion pipelines must detect structural change before applying transformation logic. Without format versioning, a silent format change produces ingestion failures that surface as unexplained progression errors, not integration errors.
- Idempotent processing. Reprocessing the same export must not create duplicate progression events or double-count assessment completions. Idempotency requires explicit deduplication logic based on a stable record identifier — not just a timestamp. Without it, retry logic after a failed job will produce corrupted progression state.
- Explicit error handling with traceable logs. Invalid rows should be isolated, logged with a specific error code and source reference, and excluded from the processing run without failing the entire batch. Silent failure — where invalid records are skipped without any trace — creates inconsistent progression states that are extremely difficult to diagnose retroactively.
These four controls are the minimum for a batch integration that can be audited and debugged. DevOps and pipeline architecture for education platforms should treat these as non-negotiable baseline requirements, not optional additions.
If your team is currently designing a batch integration for a K-12 or higher education platform — or diagnosing inconsistencies in a system already in use — the sequencing and idempotency decisions made in the ingestion layer will determine whether the progression logic can be trusted. Discuss your integration architecture with Bluepes.
Observability and reconciliation in batch-based learning systems
Batch systems introduce a structural delay between instructional events and system state updates. That delay makes logging and reconciliation architectural requirements, not operational conveniences. Without them, schools lose the ability to trace how a student moved from one mastery state to another — which creates support escalations, trust issues with teachers, and compliance gaps when institutions need to demonstrate audit readiness.
The instructional orchestration model in education platforms directly depends on reliable batch integration — if the underlying data is unreliable, orchestration logic cannot produce consistent learning sequences regardless of how well the pedagogical model is designed.
Three controls that make batch systems auditable
- Ingestion audit logs. Every file import should generate a traceable record that includes the timestamp, schema version matched, total record count, count of rejected rows, and a unique job identifier. This log is what administrators use when they need to verify that a specific sync cycle completed correctly.
- Processing checkpoints. Each transformation step that affects progression-related fields — mastery state, completion flag, grade threshold — must log the before and after values. Without per-step state logging, debugging a corrupted progression record requires replaying the entire pipeline.
- Reconciliation reports. A deterministic comparison between the source export and the processed state should be available for administrators without requiring engineering involvement. The report should identify records that appear in the source but not in the processed output, and records where processed values diverge from source values.
The NIST SP 800-53 access and audit control framework provides the technical baseline for logging requirements in regulated environments. Batch integration systems that support accreditation reporting or FERPA compliance reviews are typically evaluated against these standards.
Real-time API vs batch export: how the architectures differ
Table 1: Architectural differences between real-time API and batch export integration. Batch systems require explicit compensating controls where real-time systems rely on event-driven feedback loops.
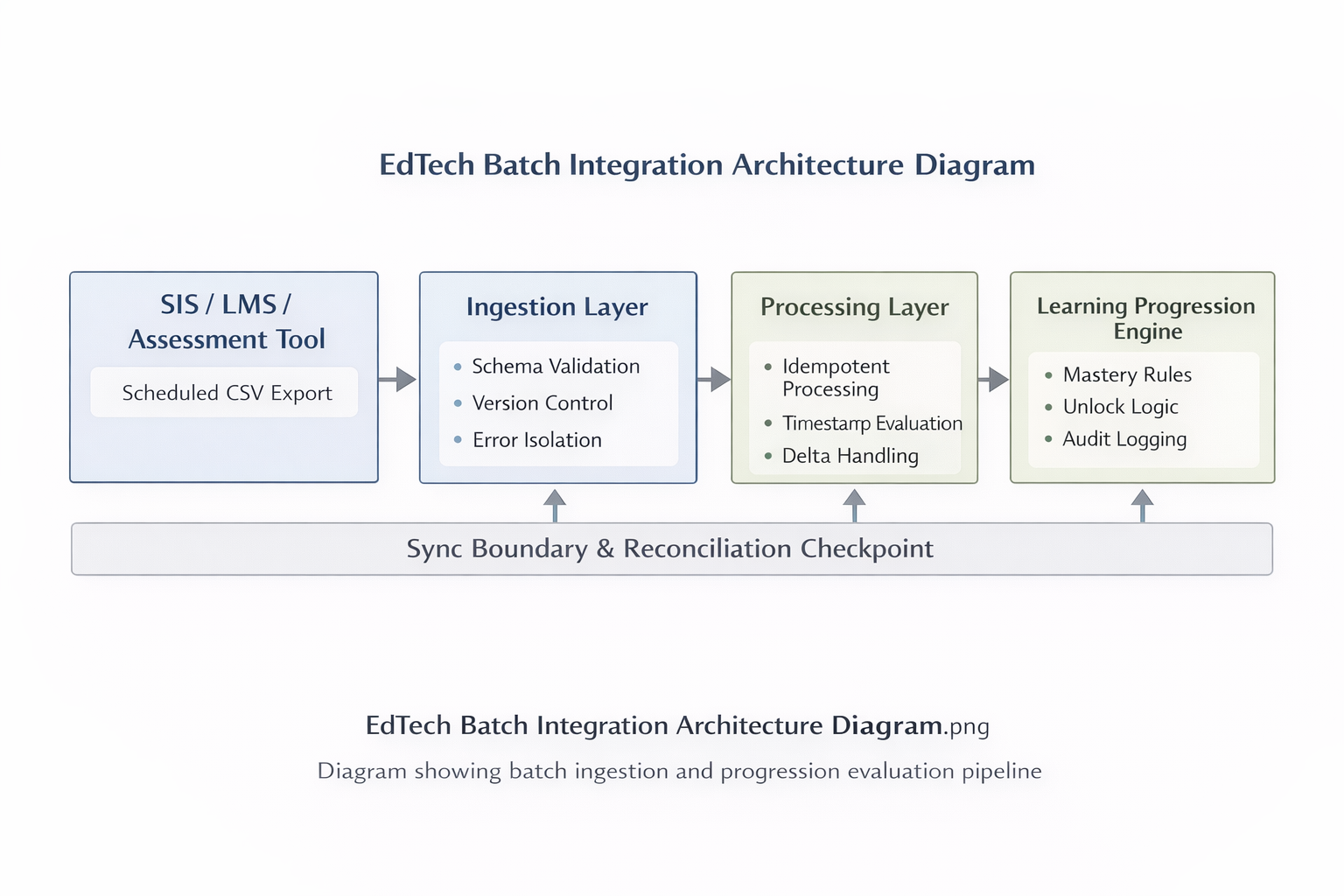
edtech-batch-integration-architecture-diagram
Figure 1: Batch integration flow showing CSV ingestion, schema validation, idempotent processing, and reconciliation checkpoints. Each step operates independently so that a failure at one stage does not silently corrupt downstream progression state.
Why driving learning logic from reports is a structural risk
Report-driven logic appears in systems where the structured data source is unavailable, inconvenient, or slow to access. A developer downloads a PDF summary, parses it with a regex, and feeds the values into a progression rule. It works — until the report layout changes in the next vendor release. At that point, the parsing rule breaks silently, progression decisions run on stale or incomplete data, and the system keeps operating without any visible error.
The deeper problem is governance. When learning logic depends on a report rather than a structured machine-readable source, it becomes impossible to trace where a specific value came from, whether it was modified in transit, and whether it reflects the actual source-of-truth state. In regulated education environments, that ambiguity creates compliance exposure. Auditors and accreditation reviewers ask precisely these questions — and a report-parsing pipeline cannot answer them cleanly.
What breaks when you build logic on report output
- Report layouts change without notice, breaking parsing rules without triggering any error in the integration pipeline.
- Silent failures accumulate — the system continues running, but decisions are based on incomplete or outdated values.
- Audit trails become ambiguous — it is unclear whether a specific progression decision reflects the actual data state or a parsing artifact.
- Data lineage disappears — there is no reliable way to trace a progression outcome back to the source record that caused it.
The IMS Global OneRoster specification defines the structured CSV exchange format that SIS and LMS vendors use for batch data sharing. Where OneRoster-compliant exports are available, they should always be the integration source — not reports, not dashboard scrapes, not PDF exports. Where they are not available, the correct approach is to work directly with the vendor on structured export options rather than building ingestion logic on top of report output.
How to reduce batch latency without breaking the architecture
When stakeholders ask for near-real-time behavior in a batch system, the request is usually not about technical architecture — it is about user experience. Teachers do not want to wait until tomorrow to see whether a student completed an assignment. Progression gates that take twelve hours to update feel broken, even when the integration is functioning correctly. Addressing that concern without abandoning the batch model requires a specific set of trade-offs.
Four approaches to reducing sync lag in batch systems
- Increase export frequency. If the SIS or assessment platform supports hourly exports in addition to nightly ones, processing those more frequent exports reduces the maximum lag significantly. This is the simplest approach and does not require changes to the ingestion architecture.
- Delta-based processing. Rather than processing the full dataset on every cycle, ingestion logic identifies only records that changed since the last export. This reduces processing time per cycle, which enables shorter intervals between runs without increasing infrastructure cost proportionally.
- Timestamp-based progression evaluation. Progression rules that evaluate whether a record is 'current' before triggering a mastery state change reduce incorrect evaluations caused by stale data. A rule that checks 'is this record newer than the current mastery state?' prevents a stale export from overwriting a more recent progression.
- Reconciliation checkpoints between cycles. Running a lightweight reconciliation between ingestion cycles — comparing processed state against the most recent export — surfaces discrepancies before the next full sync, allowing earlier detection of drift.
Each of these approaches adds operational complexity. The goal is not to simulate real-time behavior but to find the latency level that supports actual instructional needs while keeping the integration predictable and auditable. That balance is different for every deployment context and should be defined before the architecture is built, not after teachers start reporting delays.
Data normalization during pilot phase: why less is more
Early-stage pilots often over-engineer the normalization layer. The impulse is understandable — teams want to build the integration correctly from the start, so they design for the eventual full deployment rather than the actual pilot scope. The result is a normalization architecture that is too complex to validate quickly, creates dependencies between systems that do not yet exist, and introduces transformation errors that are difficult to isolate because too many things are happening simultaneously.
The correct approach for pilot integration is to ingest only the fields required to validate the specific instructional logic being tested. Composite metrics should not be derived during ingestion. Vendor fields should be preserved in their original format, with transformation logic applied separately and documented explicitly. This approach makes it easier to identify whether a progression error is caused by an ingestion problem, a transformation problem, or a logic problem — which is the core diagnostic task during any pilot phase.
Specifically, pilot integrations should: ingest only required fields and preserve the rest as raw copies; limit transformation logic to what the pilot's instructional rules actually need; document every field mapping in a format that non-technical stakeholders can review; and avoid merging multiple CSV sources until the individual sources have been validated independently. This aligns directly with pilot containment strategies for edtech — keeping the scope narrow enough that validation results are interpretable.
When batch integration architecture reaches its limits
Batch-based integration works well for most K-12 and higher education deployment contexts. There are specific situations where the model creates more problems than it solves — and those situations are worth identifying before committing to a batch architecture rather than after encountering them in production.
- Immediate compliance decisions. If progression must trigger immediately for legal or accreditation purposes — not by end of day, but within minutes — batch latency is a compliance risk, not just a UX inconvenience.
- High-frequency intraday updates. Platforms where students complete multiple assessments per hour and progression gates depend on each completion require either very high export frequency (impractical in most SIS configurations) or a different integration model.
- Unstable vendor exports. If the upstream SIS or assessment platform generates inconsistent exports — varying schemas, missing records, irregular schedules — the batch integration will produce unreliable results regardless of how well the ingestion layer is designed.
- Unclear data ownership. When multiple systems claim to be the source of truth for the same record, reconciliation becomes ambiguous. Batch integration works when the source hierarchy is defined and respected — not when it is contested.
Reaching these limits does not necessarily mean replacing the batch model entirely. It often means renegotiating integration terms with the vendor, restructuring the data ownership hierarchy within the institution, or adding a lightweight event layer for specific high-priority updates while keeping batch processing for the bulk of the data flow. The appropriate response depends on which constraint is actually binding.
Key takeaways
- Batch integration is not a fallback mode — it is the primary integration architecture for most regulated education environments, and it requires explicit design decisions rather than workarounds.
- The gap between event time and export time is structural. Progression logic must account for it explicitly, or it will produce incorrect behavior at sync boundaries.
- Deterministic ingestion requires schema validation, idempotent processing, and per-row error isolation as baseline controls — not optional enhancements.
- Observability in batch systems means ingestion audit logs, processing checkpoints, and reconciliation reports — all accessible to administrators without engineering involvement.
- Report-driven logic introduces governance risk that cannot be resolved retroactively. Structured machine-readable exports must be the integration source.
- Pilot integrations should minimize normalization scope to preserve diagnostic clarity. Over-engineering the transformation layer is one of the most consistent pilot-phase mistakes.
Building batch integration that institutions can trust
The operational impact of sync boundary failures tends to emerge gradually. Early in a deployment, edge cases where data arrives after a progression evaluation window are rare and easy to dismiss. As the student population grows and assessment frequency increases, those edge cases become consistent failure modes — and by then, the ingestion architecture is embedded deeply enough that fixing it requires significant re-engineering.
Designing deterministic ingestion, reconciliation logic, and observability controls from the start is always faster than retrofitting them into a system that has already accumulated progression errors and support debt. This is particularly true in regulated K-12 and higher education contexts, where institutional trust in the platform depends on progression logic that teachers and administrators can verify independently.
Batch integration architectures for K-12 district and higher education platforms require careful attention to ingestion pipeline design, schema validation, idempotent processing, reconciliation reporting, and FERPA data handling requirements. If you are building or evaluating a batch integration for an education platform, request an architecture review from the Bluepes integration team.
FAQ












Interesting For You



Why Most EdTech Pilots Fail: Designing a Contained Learning Path Pilot in Regulated Education
A contained learning path pilot is a structured, limited-scope validation phase designed to test instructional logic, sequencing rules, and mastery criteria without building a full production system. In K–5, K–12, and higher education environments, pilot containment reduces instructional and technical risk while preserving architectural clarity for future scaling. Overextending early pilots often increases adoption friction and governance complexity. This article explains how to define pilot scope, isolate variables, and align validation metrics with long-term system strategy. It is relevant for school leaders, EdTech founders, curriculum architects, and technology directors evaluating instructional pilots.
Read article


Instructional Orchestration vs. Software Automation in Regulated Education Systems
Instructional orchestration defines how learning sequences, mastery rules, and teacher intervention logic are structured within a digital system. Automation alone does not guarantee pedagogical alignment; orchestration requires mapping educational theory to system behavior. In K–5 and K–12 environments, sequencing logic directly affects learning progression, while in higher education it impacts curriculum pathways and credit logic. This article explains how mastery modeling, teacher override controls, and system constraints intersect in regulated learning environments. It is relevant for instructional designers, academic technology teams, and EdTech product leaders building structured learning systems.
Read article



API governance in Boomi: how mid-market teams keep control
When a mid-market company runs 50 active integrations and six product teams pushing API changes independently, governance stops being a process question and becomes a risk question. One team overwrites a shared endpoint. Another deprecates a version without notifying consumers. A partner integration breaks at 2 a.m. with no clear owner to call. Bluepes is an independent integration consulting company that works with Boomi as one of its core platforms. This article draws on that hands-on experience — not as Boomi's representative, but as a team that has debugged the consequences of missing governance and helped clients build the structures that prevent them. This article is for CTOs, VP Engineering, and IT Directors at mid-market organizations who manage growing API catalogs and want a practical governance model they can implement incrementally. Next — a breakdown of the five governance layers, how each maps to Boomi's tooling, and where teams typically lose control. API governance in Boomi means applying consistent rules for how interfaces are designed, secured, versioned, and retired. The Boomi API Management module provides the infrastructure. The design conventions, ownership assignments, and review cadences are decisions the engineering team makes. Organizations that get this right reduce integration failures, shorten partner onboarding, and make security audits straightforward rather than stressful.
Read article