SQL vs NoSQL: when each one fits your data architecture



Choosing between SQL and NoSQL for a new system used to be a near-default. Most teams reached for a relational database, and the alternative entered the conversation only when scale or schema flexibility became a hard problem. That has changed. Engineering leaders today face a real decision at the start of every new service: a managed PostgreSQL cluster, a document store like MongoDB, a key-value store like Redis or DynamoDB, or some combination of the three. The recommendations they receive often contradict each other.
This article gives a working framework for the SQL vs NoSQL decision in mid-market and growth-stage environments. It covers what each category actually solves in 2026, where each one is the correct default, where each one quietly fails in production, and how to apply a few decision criteria that hold up across analytics, transactional, and operational systems.
In short: SQL remains the right default for analytics, complex relational logic, and any workload where transactional integrity is non-negotiable. NoSQL is the right call for specific access patterns — high-volume key-value lookups, schema-flexible documents, time-series or graph data — where the relational model would force unnecessary work.
Updated on May, 2026
What "SQL" and "NoSQL" actually mean in 2026
SQL is a query language defined by the ISO/IEC 9075 standard, most recently updated as SQL:2023. NoSQL is not a single technology but an umbrella label for databases that do not use the relational model as their primary structure: document stores (MongoDB, Couchbase), key-value stores (Redis, DynamoDB, Valkey), wide-column stores (Cassandra, ScyllaDB), graph databases (Neo4j), and search-oriented stores (Elasticsearch, OpenSearch). Each of these solves a different problem.
The line between the two categories is less clean than it used to be. PostgreSQL added the JSONB type years ago and supports document-style queries against semi-structured data, full-text search, time-series extensions through TimescaleDB, and vector search through pgvector. SQL:2023 introduced an entirely new part for property graph queries (SQL/PGQ) and a native JSON data type with simplified dot-notation, as Oracle documented when the standard was published. On the other side, MongoDB has added an aggregation framework that mirrors many SQL operations, and DynamoDB has added PartiQL, a SQL-compatible query syntax over its NoSQL engine.
What this means in practice: the choice is no longer "language A vs language B". It is a choice about the underlying data model, the consistency guarantees, the query optimizer, and the operational shape of the system you are building.
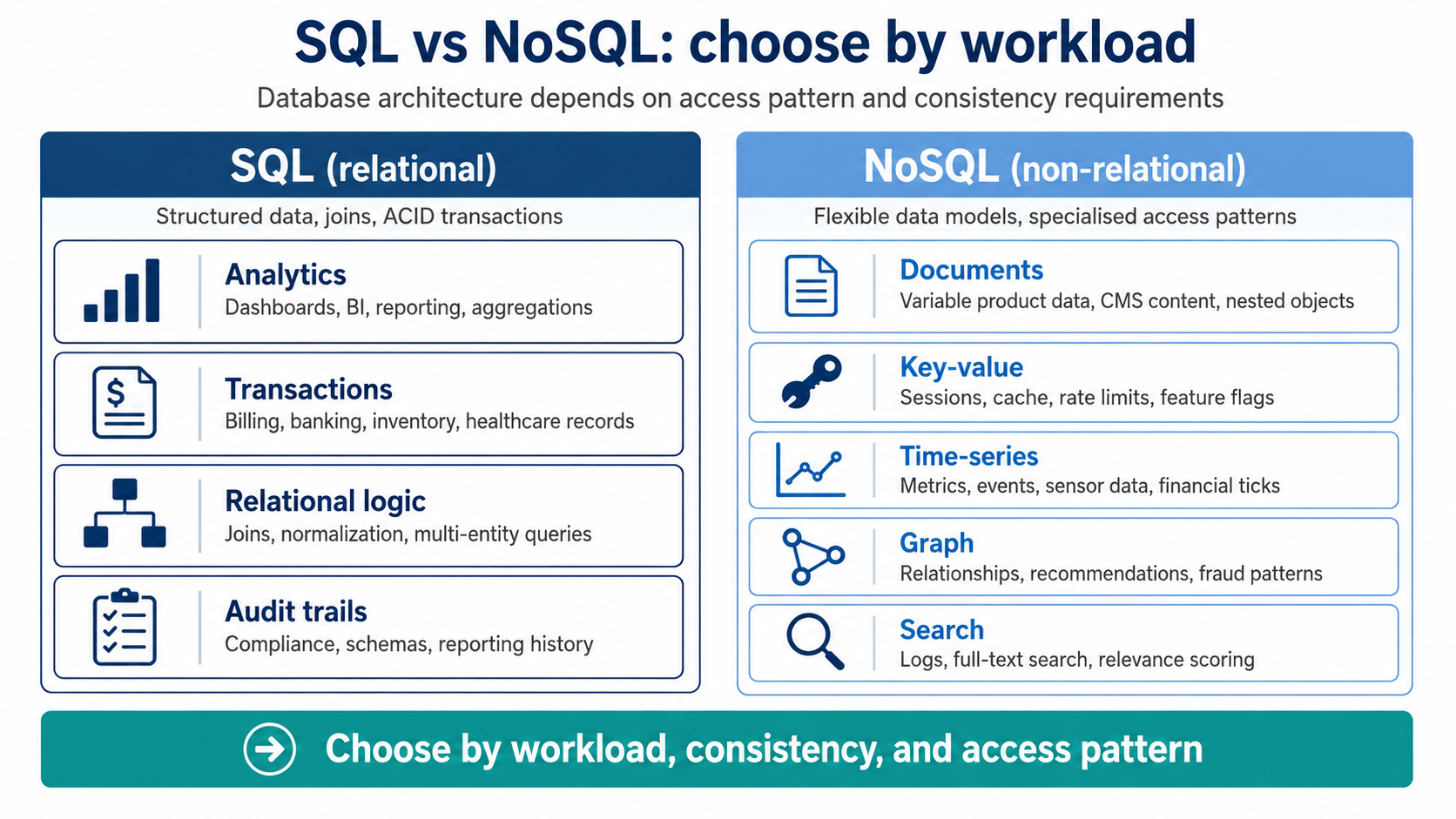
sql-vs-nosql-workload-decision-map
SQL and NoSQL decisions should start with the workload: relational analytics and transactions usually fit SQL, while document, key-value, time-series, graph, and search patterns may justify NoSQL or specialised stores.
Where SQL is still the right default
SQL remains the right default for any system where the data is fundamentally relational, where complex queries need to join across many entities, and where strong transactional guarantees matter. The Stack Overflow Developer Survey 2025 reports that SQL is the third most-used language by professional developers (61.3%), and PostgreSQL is the most-used database overall (58.2%). Seven of the ten most-used databases in that survey are relational. That ranking reflects a mature, well-supported ecosystem — not nostalgia.
Analytics and reporting
Almost every serious analytics platform is SQL-first. Snowflake, BigQuery, Amazon Redshift, Databricks SQL, ClickHouse, DuckDB, and the SQL endpoints inside Microsoft Fabric and Amazon Quick Suite all expose SQL as the primary query interface. The reason is that analytical questions — group, aggregate, join across many dimensions — map naturally to relational algebra and benefit from a query optimizer that has been iterated on for decades. Tooling for Amazon Quick Suite analytics on Redshift assumes a SQL data layer underneath, and so does almost every BI tool a non-engineer would touch. For deeper guidance on tuning the warehouse itself, see Amazon Redshift optimization for analytics workloads.
Transactional systems with strong consistency
Banking, billing, inventory, healthcare records, and any workflow where two writes must either both succeed or both fail belong on a relational database with full ACID guarantees. PostgreSQL, MySQL, Microsoft SQL Server, and Oracle all give this by default. Modern relational databases also scale further than the older "vertical-only" reputation suggests — Aurora, CockroachDB, Spanner, and Neon all distribute relational workloads across nodes while preserving SQL semantics. For fintech systems where transactional consistency is non-negotiable, the cost of getting consistency wrong is far higher than the cost of running a relational database.
Audit, compliance, and reporting trails
Schemas are a feature, not a constraint, in regulated domains. A defined schema gives a clear data contract, predictable storage size, and a foundation for audit queries that need to hold up under inspection. The PostgreSQL project itself reports that PostgreSQL conforms to at least 170 of 177 mandatory Core features in SQL:2023, with no current database management system claiming full conformance. That degree of standardisation is what makes SQL skills portable across vendors and allows compliance teams to audit query logic without learning a new dialect for every system.
If your team is currently weighing a database decision for a new product or considering a migration of an existing one, the architecture choice deserves more than a vendor comparison. Discuss your situation with our engineering team — we have built and modernised systems on both relational and non-relational stores across fintech, healthcare, telecom, and e-commerce.
Where NoSQL is the right call
NoSQL stores are the right answer when the access pattern, scale, or data shape would force a relational model into uncomfortable contortions. Three patterns come up most often.
High-volume key-value lookups
Caches, session stores, real-time leaderboards, rate limiters, and feature-flag systems share the same access pattern: look up a value by a known key, do it billions of times a day, and tolerate eventual consistency in exchange for sub-millisecond latency. Redis and DynamoDB are built for this. A relational database can be tuned to handle the same workload, but the relational structure adds overhead the workload does not need.
Schema-flexible documents and rapidly evolving data
Product catalogues with highly variable attributes, content management systems, IoT device payloads where each device sends a different shape of data, and event logs benefit from a document store. MongoDB and Couchbase let teams store nested objects directly, index on arbitrary fields, and avoid migration churn during early product iteration. PostgreSQL with JSONB is a credible alternative when relational and document workloads coexist in the same service, but a dedicated document store is often simpler when the data is genuinely document-shaped end to end.
Specialised data models — graph, time-series, search
Some data shapes are not relational at all. Social network connections, fraud rings, and supply-chain dependencies fit a graph model and run well on Neo4j or graph-native engines. High-cardinality time-series data — metrics, sensor readings, financial ticks — runs more efficiently on InfluxDB, TimescaleDB, or ClickHouse than on a generic relational store. Full-text search and log aggregation belong on Elasticsearch or OpenSearch. The right test: if the dominant query in production is a graph traversal, a time-window aggregation, or a relevance-ranked search, a specialised store will outperform a general-purpose relational database for that specific workload.
The trade-offs that surface in production
Most architecture documents present SQL and NoSQL as a clean choice. Production systems rarely cooperate with that framing. A few trade-offs are worth naming explicitly before they appear as incidents.
Polyglot persistence comes with operational cost
Adopting a second database to handle a new access pattern means a second backup strategy, a second observability story, a second authentication boundary, a second skill set, and a second on-call rotation. Teams building Java backend services that integrate SQL and NoSQL stores often find that the engineering and operational overhead of running two stores outweighs the gain from picking the "perfect" tool for each workload — until traffic or data shape genuinely demands the split.
Eventual consistency surfaces in business logic
Most NoSQL stores trade strong consistency for availability and partition tolerance. That trade-off is acceptable in many systems and unacceptable in others. A user who places an order and immediately refreshes a page expects to see that order. If the read goes to a replica that has not yet caught up, the user sees an empty cart and may place the order again. Designing around eventual consistency is a real engineering effort — read-after-write strategies, idempotency keys, conflict resolution — and it shows up in business logic, not just in infrastructure.
Analytical queries on NoSQL stores get expensive
A document store that holds operational data is not where analytical queries belong. Running a "report" that joins five collections and aggregates across millions of documents will work, but it will be slow, expensive, and brittle. The common pattern is to extract operational data into a SQL warehouse — Snowflake, BigQuery, Redshift — for analysis. The choice between batch ETL and streaming for that extraction is itself an architectural decision: see ETL and real-time data pipeline patterns for the decision criteria.
How to decide between SQL and NoSQL for a new system
Five questions, in order, will resolve most decisions before any vendor comparison.
- what is the dominant access pattern? If most reads are joins across multiple entities, SQL. If most reads are key-value lookups by a known identifier, key-value or document store. If most reads are graph traversals or time-window aggregations, a specialised store.
- do any operations require strong transactional guarantees? If yes — financial, healthcare, inventory, anything where partial failure is unacceptable — start with SQL.
- how stable is the schema? Stable schemas favour SQL. Genuinely heterogeneous data favours a document store. Note that "we are not sure yet" is not a NoSQL signal — early-stage products often think they need schema flexibility and discover later that they had a relational structure all along.
- what does the analytics path look like? If the system needs to feed dashboards, regulatory reports, or BI tools, plan the SQL warehouse layer up front, even if the operational store is not relational.
- what are the team’s actual skills? A database the team can operate confidently is worth more than a database that is theoretically optimal. Hiring for niche NoSQL operations expertise is harder and more expensive than hiring for SQL.
The table below summarises where each category fits a typical mid-market workload.
Key takeaways
- SQL remains the right default for analytics, complex relational logic, and any workload requiring strong transactional consistency.
- NoSQL is the right call when the access pattern is genuinely key-value, document-shaped, time-series, graph, or search — not as a general-purpose alternative to relational databases.
- Modern relational databases like PostgreSQL handle JSON, vector, time-series, and even graph workloads, often removing the need for a second store in early-stage systems.
- Polyglot persistence has real operational cost; adopt a second database only when traffic, data shape, or consistency requirements clearly justify the overhead.
- The most reliable decision criteria are the dominant access pattern, the consistency requirement, and the team’s actual operational skills — not vendor benchmarks.
Why the SQL vs NoSQL decision should start with the workload, not the technology
The SQL vs NoSQL question rarely has a single correct answer at the company level. It has a correct answer per workload. Most production systems end up using both — a relational store for the core transactional and analytical work, a key-value cache for hot lookups, sometimes a document store for genuinely document-shaped data. The mistake is choosing a database before understanding the dominant access pattern, the consistency requirement, and the operational cost of running it.
Bluepes engineering teams help mid-market and enterprise clients make these decisions concretely, then build the systems around them. If you are sizing a new system, modernising an older one, or deciding whether to add a second database to your stack, schedule an architecture conversation with our engineers.
FAQ












Interesting For You



Data Science in E-Commerce
More than 20 years ago, e-commerce was just a novel concept, until Amazon sold their very first book in 1995. Nowadays, the e-commerce market is a significant part of the world’s economy. The revenue and retail worldwide expectations of e-commerce in 2019 were $2.03 trillion and $3.5 trillion respectively. This market is developed and diverse both geographically and in terms of business models. In 2018, the two biggest e-commerce markets were China and the United States, with revenues of $636.1 billion and $504.6 billion respectively. Currently, the Asia-Pacific region shows a better growth tendency for e-commerce retail in relation to the rest of the world. Companies use various types of e-commerce in their business models: Business-to-Business (B2B), Business-to-Consumer (B2C), Consumer-to-Consumer (C2C), Consumer-to-Business (C2B), Business-to-Government (B2G), and others. This diversity has emerged because e-commerce platforms provide ready-made connections between buyers and sellers. This is also the reason that B2B’s global online sales dominate B2C: $10.6 trillion to $2.8 trillion. Rapid development of e-commerce generates high competition. Therefore, it’s important to follow major trends in order to drive business sales and create a more personalized customer experience. While using big data analytics may seem like a current trend, for many companies, data science techniques have already been customary tools of doing business for some time. There are several reasons for the efficiency of big data analytics: · Large datasets make it easier to apply data analytics; · The high computational power of modern machines even allows data-driven decisions to be made in real time; · Methods in the field of data science have been well-developed. This article will illustrate the impact of using data science in e-commerce and the importance of data collection, starting from the initial stage of your business.
Read article


What is Data Science?
In recent years, data science has become increasingly prominent in the common consciousness. Since 2010, its popularity as a field has exploded. Between 2010 and 2012, the number of data scientist job postings increased by 15 000%. In terms of education, there are now academic programs that train specialists in data science. You can even complete a PhD degree in this field of study. Dozens of conferences are held annually on the topics of data science, big data and AI. There are several contributing factors to the growing level of interest in this field, namely: 1. The need to analyze a growing volume of data collected by corporations and governments 2. Price reductions in computational hardware 3. Improvements in computational software 4. The emergence of new data science methods. With the increasing popularity of social networks, online services discovered the unlimited potential for monetization to be unlocked through (a) developing new products and (b) having greater information and data insights than their competitors. Big companies started to form teams of people responsible for analyzing collected data.
Read article


A Brief History of Data Science
Data science, AI, and Big Data have been the biggest buzzwords of the technological world over recent years. But even though there’s a lot of marketing fluff involved, these technologies do make a real difference in highly complex industries like healthcare, financial trading, travel, energy management, social media, fraud detection, image and speech recognition, etc. With the digitalization of the world economy and virtually every aspect of life, data has become the new oil (a term coined by Clive Humby). Subsequently, data science has become the sexiest job of the 21st century. But that’s really cutting a long story too short. Let’s look at the development of data science in more detail.
Read article