Dedicated Engineering Teams in Europe: How the Pod Works



A common scenario in European mid-market teams: the CFO has signed off on a BI consolidation programme, the integration partner is contractually committed to deliver in Q2, and the internal hiring pipeline shows zero senior Java or BI candidates over the next three months. The CTO has two options on the table — bring in three contractors through staff augmentation, or stand up a dedicated engineering team that owns the work end-to-end. The difference between the two approaches becomes visible somewhere around week six.
A dedicated engineering team for Europe is a stable pod with a Tech Lead, embedded QA, shared DevOps, and two to four engineers, contracted under EU-aligned data processing terms and accountable for delivery health metrics rather than billable hours. The model fits long-running workstreams where context and small improvements compound — integration, data and BI, platform reliability — and breaks down on isolated four-week proofs or sub-50-person organisations without a product owner inside the company.
The sections below describe the model in working detail: pod composition, the weekly cadence that produces honest signal, the procurement artefacts EU buyers typically request, and a 30-day onboarding pattern that proves delivery on one workstream before any scope expansion.
Updated in June, 2026
What a dedicated engineering team in Europe actually does
A dedicated engineering team is a contracted pod that takes ownership of a defined workstream — backlog, non-functional requirements, releases, and post-release fixes — for the length of an engagement. The structural difference from staff augmentation is the accountability boundary: an augmented contractor is responsible for completing assigned tickets, while a dedicated pod is responsible for the workstream’s delivery health, including the decisions that shape it.
For European mid-market clients, this distinction matters in two ways. Internal engineering management capacity is already constrained, and there is no spare VP of Engineering available to coordinate five contractors through daily standups. At the same time, the work that European mid-market companies typically outsource — ERP–CRM integration, BI consolidation, platform modernisation — is multi-quarter work where context and accumulated decisions matter more than individual ticket throughput. A dedicated team retains both context and decision-making capacity across the engagement; an augmented contractor relationship resets every time someone rotates off.
The integration overload that pushes mid-market IT teams toward outside help is well-documented — every new system added to the stack increases coordination cost on the existing ones (see how integration overload traps engineering teams). A dedicated team’s role in that context is to absorb a workstream entirely, not to add headcount to an already-overloaded internal queue.
Pod composition: why structure matters more than headcount
Pod composition determines whether a dedicated team functions as a delivery unit or as a group of contractors with shared invoices. A working pod for European integration, data, or BI work has four parallel roles that each carry a specific responsibility:
- A Tech Lead with delivery authority — owns architecture, code review standards, and the operating cadence. When this role is staffed at the wrong seniority or without decision-making mandate, the pod degrades into ticket-takers within four to six weeks.
- Two to four engineers matched to the workstream — Java/JVM and React for integration and product work; SQL, semantic-model, and dashboard engineers for data and BI work. The skill mix is workstream-specific and is set in week one, not flexed weekly.
- Embedded QA from week one — working alongside engineering, with test automation where the failure cost justifies it. Late-bound QA produces unstable releases that erode stakeholder trust faster than slow delivery does.
- Shared DevOps or SRE — for environments, CI/CD pipelines, and observability. Shared rather than dedicated because most workstreams do not generate full-time DevOps load, and a shared specialist brings standard tooling and pipeline patterns across pods.
Composition fails most often in one of two ways. The first is a Tech Lead without delivery authority — the pod becomes reactive, ticket-driven, and dependent on the client’s engineering manager for every architectural decision. The second is an unbalanced engineer skill set — for instance, three backend engineers assigned to a BI workstream that actually needs a semantic model designer and a data engineer. Both failures surface in the same place: delivery health metrics drift, and stakeholders start asking for ‘more hours’ when the actual constraint is composition.
Bluepes structures its dedicated development team model around this pattern by default, with deliberate decisions on which roles flex and which stay fixed for the length of an engagement.
The operating cadence that keeps delivery visible
A dedicated team’s operating cadence is the mechanism that turns pod activity into something the client can see and act on. The cadence that holds up under multi-quarter engagements has three layers: a weekly forecast and review, a daily asynchronous status, and a quarterly look-ahead.
The weekly layer carries most of the signal. At the start of each week the Tech Lead publishes a two-week forecast — what the pod intends to complete, with explicit dependencies and exit criteria. At the end of the week, a 30-minute demo shows what actually shipped against that forecast. Variance between forecast and delivery is the single most informative metric the model produces, because it surfaces scope creep, dependency drag, and quality issues earlier than any other signal.
The daily layer is asynchronous: a shared channel with ‘done / next / risk’ entries from each engineer. Synchronous daily standups add overhead in a properly composed pod; the more useful signal for stakeholders is a searchable record of progress in a shared channel that anyone can read at any time. The quarterly layer addresses capacity, sequencing, and compliance milestones — anything that needs client-side decisions and procurement involvement.
Delivery health metrics on a dedicated pod should be few and honest. The four metrics published by the DORA research program — deployment frequency, lead time for changes, change failure rate, and mean time to restore — work as a baseline for product and platform engineering pods. For integration and BI work specifically, escaped defects per release and refresh-time variance carry more signal than deployment frequency, which is misleading when releases are batched around business windows. The practical rule: choose five metrics, publish them weekly without exception, and treat outliers as prompts for a root-cause note rather than for blame.
Observability design matters as much as metric selection — failure-mode mapping for distributed systems helps the pod build dashboards around the failure types that actually occur in production, instead of around a generic monitoring template that catches nothing useful at 3 a.m.
If your team is running an integration, BI, or platform modernisation workstream under a fixed Q2 commitment, and the internal hiring path will not realistically close before then, the timing of a dedicated pod conversation matters more than its outcome. Discuss your delivery model with Bluepes engineers — the call is scoped against your existing systems, not a generic pitch.
Compliance and procurement: what European buyers ask for
European procurement teams evaluate vendors against a documented set of privacy, traceability, and access-control criteria. A dedicated team engagement that takes more than four weeks to clear procurement usually fails on documentation, not on commercial terms. The artefacts an EU mid-market engagement requires are predictable enough to prepare in advance.
The contractual foundation is a Data Processing Agreement with Standard Contractual Clauses, aligned to GDPR Article 28. The DPA must list sub-processors and require notice before any are added; sub-processor chain ambiguity is one of the most common procurement-stage blockers. Beyond the DPA, a data residency commitment for logs, backups, and any persistent storage carries real weight — most EU buyers default to EU/EEA residency, while some regulated sectors require specific member-state hosting.
Access controls are evaluated against four conditions: named accounts (no shared credentials), multi-factor authentication on every account, least-privilege role assignment, and a documented joiner-mover-leaver flow that grants access through ticket, reviews monthly, and revokes on rotation or exit. Audit logging for sensitive actions and administrative changes is expected, retained for whichever period the client’s compliance regime requires (HIPAA, SOC 2, PCI DSS, or sector-specific equivalents).
Build and delivery controls — software composition analysis, static analysis, license-policy enforcement in CI/CD — prevent unreviewed dependencies from reaching production. What shortens procurement, beyond the artefacts themselves, is preparation: a vendor assessment pack containing the DPA template, sub-processor list, access matrix, encryption summary, and incident-response baseline can be sent on day one of conversations. Without it, the assessment turns into a back-and-forth that adds six to ten weeks to the start date.
Work that fits a dedicated pod (and work that does not)
A dedicated team’s structural advantage is sustained context. The work where this advantage compounds tends to share three properties: it runs longer than a quarter, it generates downstream consequences the pod needs to own, and it touches systems where one engineer cannot hold the full picture.
Integration and iPaaS workstreams sit at the top of the fit spectrum — Boomi flows across ERP and CRM, REST-based partner APIs, idempotency design, dead-letter queue handling, and consumer-driven contracts in CI. These are systems where every new connection increases the maintenance surface, and where a Tech Lead who has been with the workstream for six months makes better trade-off calls than a fresh consultant can in the same situation.
Data and BI platforms fit the same pattern: semantic model design, KPI governance, RLS, partition and aggregation strategy, cost-aware refresh schedules. The operating model for mid-market BI describes the role split a dedicated BI pod typically uses — Power BI engineer, data engineer, BA — and the failure modes when one of those roles is missing.
Platform engineering and service reliability work — circuit breakers, backpressure, latency budgets, observability tied to on-call action — also fits, particularly when the platform handles regulated-industry load. Bluepes’s long-running telecom platform engagement is an example of the pattern over an extended timeline: multi-year dedicated team engagement on high-load infrastructure, where the value of accumulated context outweighed any short-term rate advantage from rotating contractors.
Where the model does not fit: four to six-week proof-of-concept work; isolated one-off tasks like a single dashboard or a single API endpoint; engagements where the client has no internal product owner to direct prioritisation; and very small organisations (under 50 employees) where engineering decisions are still in a founder’s head and the operating overhead of a pod exceeds the benefit. For those situations, a proof-of-concept engagement or selective engineering services across backend and frontend usually fits the timeline and scope better.
A 30-day onboarding pattern that proves the model before scaling
The most common failure mode of a dedicated team engagement is over-committing scope in the first month and discovering the gap between forecast and delivery in month three. The pattern that prevents this scopes month one as a single workstream demonstration — one pod, one slice, measurable result — and treats scope expansion as a week-five decision rather than a contractual assumption.
Week 1 — Discovery and access
Discovery brief covering problem, current systems, constraints, and non-functional requirements. Draft of the living Statement of Work with scope, exclusions, acceptance criteria, and a change log attached. Access provisioning: named accounts, MFA, least-privilege role assignment, secrets moved to vault. Baseline delivery dashboard published with the metrics the pod will report weekly.
Week 2 — First vertical slice
The pod selects a thin slice — one Boomi flow, one BI model page, one service endpoint — and implements it against the Definition of Done: tests, runbook, release notes, rollback plan. CI/CD gates active (unit and contract tests, linters, SCA/SAST). First weekly metrics and decision log entry published.
Week 3 — Observability and compliance evidence
Logs, metrics, and traces wired into a simple on-call view, with SLOs defined where the workstream has them. Vendor assessment pack prepared and delivered to procurement (DPA, sub-processor list, access matrix, security controls, backup and DR notes). Risk cadence established — top risks surfaced weekly with owners and next steps.
Week 4 — Second slice and measured signal
Extend to a second slice with the same cadence — small batch, release notes consistent, rollback tested. Capture before/after data for one concrete pain point: refresh duration, incident count, query cost, or release frequency. Publish the result in the same dashboard as the delivery metrics.
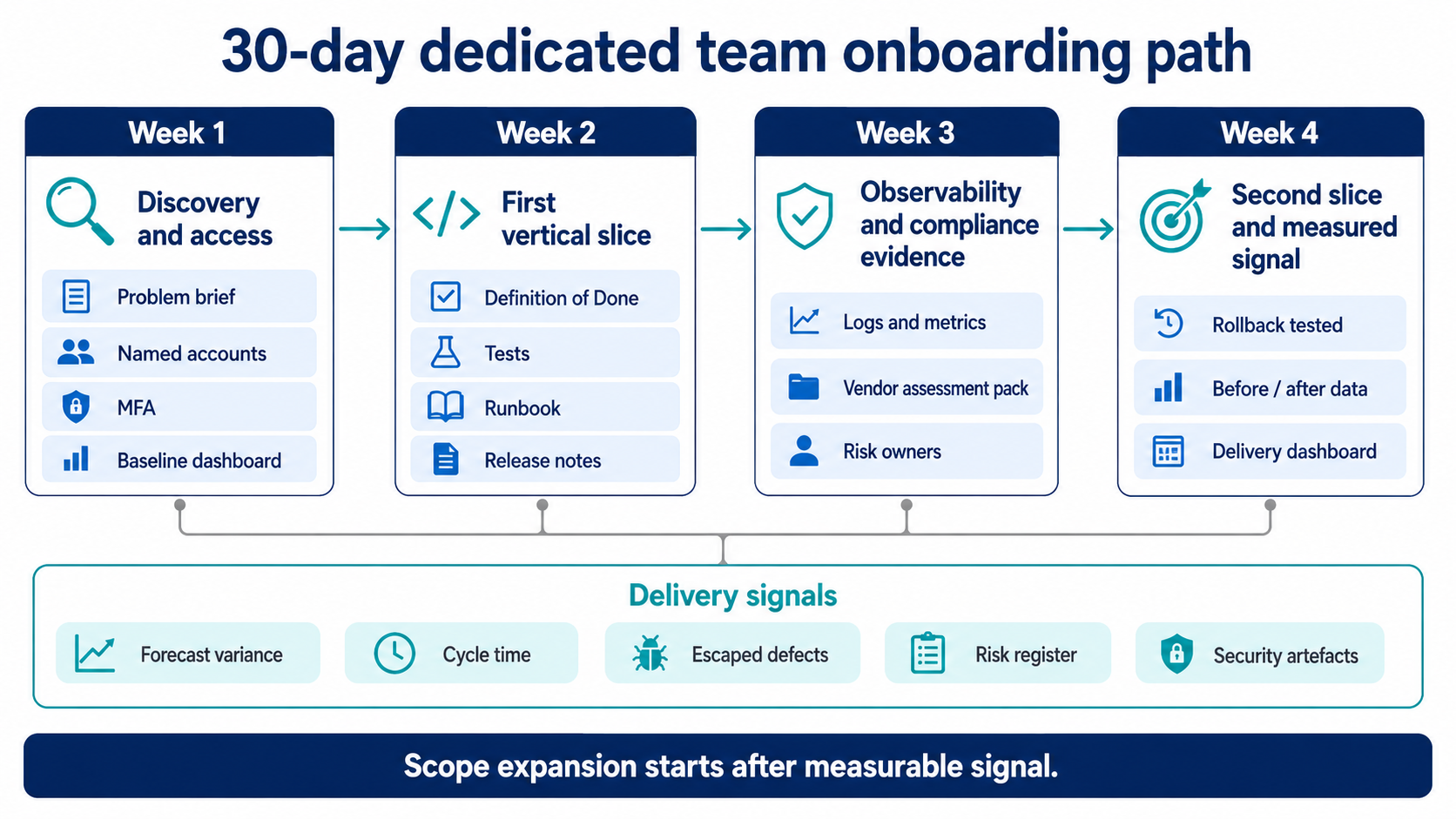
dedicated-engineering-team-onboarding
The first 30 days should prove the dedicated team model on one controlled workstream: access, first slice, observability, compliance evidence, second slice, and measurable delivery signal.
Signals that the model is working
- Forecast-to-delivery variance narrows week over week as the pod learns the workstream’s real constraints.
- Cycle time from start to production stabilises as blockers either get removed or get sequenced into the forecast.
- The risk register shrinks or stays steady; new risks appear with named owners and assigned next steps before they reach quarter-end review.
- Security artefacts exist and pass review — access logs are populated, audit trails are queryable, release gates fire on policy violations.
- Stakeholder confidence rises because changes are small, visible, and reversible, and demos show working software rather than slide updates.
If these signals are absent at week four, the diagnosis is usually one of three things: a Tech Lead without delivery authority, a misaligned engineer skill set for the workstream, or scope wider than one pod can absorb in a first month. All three are correctable, but the correction has to happen before scope expansion, not after.
Key takeaways
- A dedicated engineering team for Europe is structurally accountable for a workstream’s delivery health, not just for ticket completion — which makes the model appropriate for multi-quarter work and inappropriate for isolated tasks.
- Pod composition (Tech Lead with delivery authority, embedded QA from week one, balanced engineer skill set, shared DevOps) determines whether the pod operates as a delivery unit or as managed contractors.
- The operating cadence — weekly forecast and review, asynchronous daily status, quarterly look-ahead — converts pod activity into visible delivery signal for stakeholders.
- European procurement is solved on documentation; a prepared vendor assessment pack covering DPA, SCCs, access matrix, and security controls shortens onboarding by six to ten weeks.
- A 30-day onboarding pattern proves the model on one slice before scope expansion; absence of the right signals at week four is correctable, but only if diagnosis precedes scaling.
How a dedicated team engagement holds up over multi-quarter work
A dedicated engineering team in Europe is a structural answer to a specific constraint: internal hiring is too slow, augmentation overhead is too high, and the workstream needs sustained context that rotating contractors cannot hold. The model works where it fits — integration, data and BI, platform engineering — and fails where the underlying conditions are wrong, such as in short engagements without an internal product owner or in organisations where the operating overhead exceeds the gain.
What separates a working dedicated team from an expensive staff-augmentation arrangement is rarely the rate card. It comes down to three structural elements: whether the pod has a Tech Lead with authority to make trade-offs, whether the cadence produces honest signal instead of activity theatre, and whether the procurement artefacts exist on day one. The first month proves all three. Request a structured dedicated team proposal — Bluepes engineers scope the workstream, propose pod composition, and outline a 30-day onboarding plan against the systems already in place.
FAQ












Interesting For You



How to Choose a Software Development Partner in Ukraine?
Nowadays, Ukraine is considered one of the best countries to work from if you are in the IT sector. While the current level of general economic growth is modest, the software industry has been blooming for the past decade, attracting more talent and creating a stable network of professionals.
Read article



Why businesses are rethinking their integration strategy
Most IT teams don't notice integrations until something breaks at the worst possible moment. A new CRM rolls out, and three weeks later someone in finance discovers that customer data hasn't been syncing. An ERP upgrade ships on schedule and quietly disables five automated workflows that nobody documented. Revenue numbers look wrong in the dashboard because two systems are still running on different update cycles. This article is for CTOs, IT Directors, and VP Engineering roles who suspect their current integration architecture costs more to maintain than it should — in engineering hours, in delayed releases, and in recurring data quality incidents. Next — a clear breakdown of where standard approaches fail, what modern platforms actually offer, and how companies in healthcare, e-commerce, and finance are handling this shift in practice. Business integration modernization — replacing a fragmented collection of point-to-point connections with a centralised, scalable architecture — has become a priority for companies that have grown past their original tech stack. The pressure isn't coming from trend reports; it's coming from the compounding overhead of keeping legacy connections alive as systems multiply.
Read article



How companies are future-proofing their tech stacks with cloud-native integration
The average mid-market company runs dozens of business applications: an ERP, a CRM, a separate billing system, various cloud tools, and increasingly AI-powered services layered on top. Each of those systems generates data the others need. Keeping them connected is no longer an IT side project — it is a condition for the business to function. This article is for IT Directors, CTOs, and technical leads who are managing integration infrastructure built for a smaller, simpler stack. If your team spends more time fixing broken connections than building new capabilities, this is for you. Next — a look at what future-proofed companies actually do differently, and what a more sustainable architecture looks like. The short answer: companies that scale without constant integration disruption tend to have moved away from custom-built, point-to-point connections and toward managed integration platforms. Boomi is one of those platforms. Bluepes is an independent software consulting company that works with Boomi and other integration tools on behalf of clients — this article reflects that perspective, not Boomi's marketing position.
Read article